写在开头
本文未完全完工,持续更新中。对自己的阅读速度太自信了,实际上这个二百多页的东西确实量大。而且有时我会发散到一些参考资料上,速度就更慢了。先放一部分,后续持续更新吧。
这是最近很火的《The Smol Training Playbook: The Secrets to Building World-Class LLMs》,由huggingface团队整理,分享了一些顶尖语言模型训练过程中的实际经验。全文214页,算是类似指南吧。
原本写了一堆关于大模型开源闭源的废话,跑题全删了。总而言之,如此开源程度的工作越来越少了。我希望能够无比珍惜的一句一句啃下来,不使用AI总结等等(希望我能不失去阅读长文的耐心和注意力),就像去年一句一句啃Llama-3技术报告时一样。 话虽如此,我并不打算逐字逐句进行翻译,我可能只会对我感兴趣/有感触的句子进行摘抄和记录。本文是边读边做的笔记,所以格式会有点乱。内容大体来说分三级: 引用块 -> 正常文本 -> 斜体下划线。其中引用块是原文摘抄,正常文本是个人对原文的理解/总结,斜体下划线是个人感想/题外话。
图表会直接从文中复制,如果不是出自本文的图表我会特别注明出处。但本文毕竟是单人写的读书笔记/超长博客,如果要维护规范的引用实在有心无力,我只能保证每一处引用都会有链接/论文名称/项目名称其中之一,不能保证都有,尤其是链接。时间精力有限,并不规范,还请见谅。
为了避免一些名词翻译造成的混淆,一些名词/术语我会使用英文。
以下是正文:
Introduction
这篇文章是训练SmolLM3的纪实,一个3B多语言模型(在11T token上训练)。
文章也提了:214页太长,没必要一页一页看完,这文章包含了几个主要的部分,相对比较独立:
- 训练指南:比较high-level,给你个决策树帮你判断应不应该训模型,我会丢个图然后跳过这部分。
- 预训练:continuous(增量)预训练或者从零开始(from scratch),怎么跑消融、怎么评测、怎么混合不同数据、怎么选结构、怎么调参,我会集中精力在数据混合上。
- 后训练:包括SFT、DPO、GRPO等技术以及背后的黑手(黑手!),这部分全文将会是我阅读的重点。
- Infra:如前所述,千卡/万卡集群的运维是一个非常庞大的工程难题。Meta曾经提过他们32k卡的集群在训练期间的利用率大约是30~40%,足以证明这个问题的难度与重要性。但我不关心,不看。我对infra不太了解,如果感兴趣可以同时看一下一个非常早期的实现bloom-176B,其中主要内容是模型训练过程,但也包含了infra的部分经验;bloom-176B掏出了Megatron-Deepspeed,后来微软在维护一个新的Megatron-Deepspeed,我曾经用后者
Megatron-Deepspeed训模型时bloom的实现是几个主要的参考资料来源之一。
训练指南——Training Compass: Why->What->How
high-level的训练指南
Why:到底要不要训
graph TD
A[该训练属于自己的模型吗] --> B[现有的模型能不能handle你的问题]
B -->|Yes| C[现有的模型用prompt就能handle]
C --> E[别训了 用现有的]
B -->|No| D[用prompt做不好]
D --> F[微调能解决吗]
F -->|Yes| G[微调有用 包括增训和后训练]
G --> H[别从零开始训]
F -->|No| I[微调解决不了]
I --> K[只训下面类型的模型]
K --> L[科研]
K --> M[生产场景]
K --> N[战略性开源]
针对需要from scratch的三种情况
- 科研,有一些已经探索过的问题可以参考:
- 月之暗面:Muon优化器能否scale到10B以上的模型?paper 作者之前提过,很多小模型上很好看的技巧无法扩展到大模型,kimi-k2把Muon扩展到了1T参数模型上,很有实力
- Deepseek:直接上强化学习能产生推理能力吗?著名的Deepseek R1,当然我会认为这是预训练阶段退火使用instruction数据导致base模型实际上已经接近instruct模型
- 微软:用纯合成的数据训模型能训出比较好的小模型吗?微软的Phi系列模型,但很早了,做法类似蒸馏,当时社区有很多人怀疑数据泄漏,建议主要看看phi1和phi4
- 多机构:只用合法的数据训练能训出好模型吗?没关注到这篇,提出了一个8TB的数据集,私以为这种研究是非常有意义的
- 生产,有三个主要原因
- Domain specific:这是最常见的,以我在做的事为例,大语言模型的化学能力非常差,主要是由于缺乏领域知识。
- Deployment constraints:比如硬件、吞吐延迟等等
- Goverance
- 战略性开源
What:你该训什么?
包括模型类型、模型尺寸、结构细节和数据策略。你会根据你的需求,做出最合适的选择。其中前三者相对比较好确定,数据策略是一个比较说不清的黑盒,是各个公司的技术核心内容,有的公司可能会给出自己的数据配比,但为何做出这样的选择也是不明确的,当然我们肯定可以排除随便拍脑袋定的或者纯看结果定的。这可能类似材料科学,的确是结果说话,但在得到结果之前的先验知识也是必须的,否则没人能负担大模型重复训练的消耗。
大体上可以把决策过程分为两阶段:
- Planning:根据你的需求(“Why”),做出最合适的选择
- Validation:进行系统性的测试,也就是做消融(ablation)
Superpower:速度和数据
迭代速度:模型训的勤快、你的团队也会更好。我大约23年时有这样的明显感觉:我训模型的同时模型也在训我,告诉我应该怎么选择数据和超参,怎么预估训练结果。
数据:高质量数据的影响大于模型架构。不必多说,大家都喜欢研究架构,但大家也都承认不如搞数据
团队规模:影响迭代速度,主要的预训练任务只需要几个人,比如预训练Llama3这样的模型可能只需要2~3个人。
预训练——Every big model starts with a small ablation
正式训之前需要通过消融来确定架构、optimiser、学习率调度、数据混合。光靠想是想不明白的,比如直觉来说用大量arxiv论文训练模型的效果应该会很好(高质量数据),但实际上不然。因为模型需要的是多样性,而不是狭隘的高质量
机器学习不是纯数学,而是一门实验科学,实验将会指导关键决策。这些实验需要满足以下两点:
- 速度:快速迭代。
- 可靠性:提供强大的区分能力。作为ablation,最重要的就是独立变量,stand alone
但在消融之前其实我们就得做关于模型架构和大小的选择。也就是选择一个baseline。
Choosing your baseline
在一个别人验证过的基础模型上做自己的修改,比如Qwen是从llama架构开始的,kimi是从Deepseek v3开始的。实际上在MoE爆火之前绝大多数实践都是从llama架构开始的,我曾经搭建过自建模型,也是完全仿照llama3(和llama2的最主要区别在于小号模型也引入了GQA,除此之外没啥特别的。站在巨人的肩膀上大概率会得到一个好的工程实践,否则你需要把复杂现实中所有的坑都踩一遍,注意以下:
- 匹配你的约束:硬件、使用需求
- 大规模验证过的:吃过几T token还稳定的模型
- 有良好的文档:已知的超参,并且在开源模型中证明过有效。这很重要,尤其是对于没有几百号工程师的团队来说,最好能找到类似的开源实践,包括bloom、GPT-Neo等等
- 框架支持:训推框架的支持
以下是一些推荐选择:
| Architecture Type | Model Family | Sizes |
|---|---|---|
| Dense | Llama3.1 | 8B, 70B |
| Dense | Llama3.2 | 1B, 3B |
| Dense | Qwen3 | 0.6B, 1.7B, 4B, 14B, 32B |
| Dense | Gemma3 | 12B, 27B |
| Dense | SmolLM2, SmolLM3 | 135M, 360M, 1.7B, 3B |
| MoE | Qwen3 MoE | 30B-A3B, 235B-A122B |
| MoE | GPT-OSS | 21B-A3B, 177B-A5B |
| MoE | Kimi-moonlight | 16B-A3B |
| MoE | Kimi-k2 | 1TB-A32B |
| MoE | Deepseek v3 | 671B-A37B |
| Hybrid | Zamba2 | 1.2B, 2.7B, 7B |
| Hybrid | Falcon-H1 | 0.5B, 1B, 3B, 7B, 34B |
| MoE+Hybrid | Qwen3-Next | 80B-A3B |
| MoE+Hybrid | MiniMax-01 | 456B-A46B |
可以先从这个架构开始,不用想太多。后面再改
Modifying Your Baseline
现在考虑怎么改架构,因为无论怎么改架构都会带来大量风险,所以一个基本原则降低风险:除了你测试过有用的内容之外,不要改任何东西。
什么算有用?
- 提高你的目标能力
- 提供有意义的好处:推理更快、内存更低、训练更稳定
但很麻烦的点在于:有太多东西能改了:注意力、位置编码、激活函数、优化器、超参、归一化、布局。这些组件之间非线性作用,你肯定不能把这些玩意儿的笛卡尔积全测一遍。
先测一些有希望的变化,如果比起baseline生效了,就集成进来成为新的baseline。
以我个人的经验来说(不保对),优化器、激活函数和归一化对训练稳定性有很大的影响;layout(如果这里特指各个矩阵维度和层数的话)对特定任务的性能有比较大的影响;位置编码没必要做太多改动,可以相对安心地用RoPE,除非你想做超级长上下文;注意力是核中核,毕竟大家都忍不了n^2复杂度,这也是提高推理速度、内存占用最大的优化点,但遗憾的是这部分的修改也是最具难度的,不然大家也不会一个GQA用这么久;超参是训练技巧了,边看曲线和checkpoint的测试结果边调整吧
Picking a training framework
框架要考虑三个因素:
- 必须支持目标架构
- 稳定且能用于生产,不能训一半莫名其妙崩了
- 吞吐性能比较好看
| Framework | Features | Battle-tested | Optimised | Lines of Code (core / total) | Extensibility & Debugging |
|---|---|---|---|---|---|
| Megatron-LM | ✅ Extensive | ✅ Kimi-K2, Nemotron | ✅ Pioneers of 3D parallelism | 93k / 269k | ⚠️ Hard for beginners |
| DeepSpeed | ✅ Extensive | ✅ BLOOM, GLM | ✅ Pioneers of ZeRO & 3D parallelism | 94k / 194k | ⚠️ Hard for beginners |
| TorchTitan | ⚡ Growing feature set | ⚠️ Newer but tested by PyTorch team | ⚡Optimised for dense models, MoE improvements underway. | 7k / 9k | ⚡ Moderate: requires parallelism know-how |
| Nanotron | 🎯 Minimal, tailored for HF pretraining | ✅ Yes (StarCoder, SmolLM) | ✅ Optimised (UltraScale Playbook) | 15k / 66k | ⚡ Moderate: requires parallelism know-how |
说实话没用过下面两个,个人觉得,对于正儿八经想做东西的,还是多花点功夫学习一下Megatron-LM,经过了大量的实战检验,有较多的社区支持(比如文档);后训练就能搞定的,有一个更beginner的选择:transformers+trl自带的trainer,用起来足够方便而且能集成Deepspeed,而且有大量的套壳框架,比如llamafactory等等。
Ablation Setup
放这段在消融的最前面:
The real value of a solid ablation setup goes beyond just building a good model. When things inevitably go wrong during our main training run (and they will, no matter how much we prepare), we want to be confident in every decision we made and quickly identify which components weren’t properly tested and could be causing the issues. This preparation saves debugging time and bullet proof our future mental sanity.
Setting up our ablation framework
主要两种方法:
- 目标模型大小,但数据很少
- 小模型,但问题在于小模型上的发现能不能scale到大模型上。
In our experience, if something hurts performance at small scale, you can confidently rule it out for large scale. But if something works at small scale, you should still make sure you’ve trained on a reasonable number of tokens to conclude with high probability that these findings will extrapolate to larger scales. The longer you train and the closer the ablation models are to the final model, the better.
作者团队做消融的配置参考:1B 的transformer(llama3.1架构),45B token,nanotron框架,在8卡H100上大概要1.5天,单卡每秒吞吐42k token(???这么快???)。具体参数和数据配比看原文吧,大致看上去是通用:python:数学=7:2:1。有点奇怪,这里20%代码数据我没意见,但怎么只有python?光靠通用数据里的其他语言够吗?要知道编程语言的设计思路差距还是挺大的,光靠python能scale到其他语言?我有点疑惑。
然后为了公平的跑ablation,如果你的一些修改改变了模型参数(比如attention、tied embedding),那就得调整它的其他参数(比如层数、hidden size),把参数变回来。
这里作者给了个根据不同超参算dense模型总参数量的计算器,我不引了,推一下公式大家自己算吧:
$$\begin{aligned}\text{Total Params} &= \text{Embedding Params} + \text{Layer Params}\times\text{Layer Count} \\ &= [\text{Vocab Size}\times\text{Hidden Size}]\times \text{isTied} + [\text{Attention}+\text{FFN}+\text{Norm}]\times\text{Layer Count}\\ &= [\text{Vocab Size}\times\text{Hidden Size}]\times \text{isTied} + [\text{Hidden Size}^2\times(2+2\times\frac{kv\_heads}{num\_heads}) + \text{Hidden Size}\times\text{Inter Size}\times3 + \text{Hidden Size}\times2] \times\text{Layer Count} \end{aligned}$$其中 $\text{isTied} = \begin{cases}1,\quad tied=true\2,\quad tied=false\end{cases}$。
*比较基础,简单解释一下:
- tied 标记了输出的embedding矩阵是不是输出的转置,所以如果tied,这两个矩阵是共享参数的;
- kv head/num head是GQA的配置,当这个比值为1的时候退化成普通的MHA;
- FFN有3个是因为 gated up proj 占俩、down proj 占一个;
- Norm这个$2\times\text{Hidden Size}$是针对Llama架构常用的RMSNorm:$\text{RMS Norm}(x_i)=g_i\times(\frac{x_i}{\sqrt{\frac1n\sum_i x_i^2+\text{eps}}})$,其中eps是一个防止除0的小数,而 $g_i$ 是可学习的权重。如果你 Layer Norm,那除了权重之外还有个偏置项,这个参数量要翻倍的。*
Understanding what works–evaluation
消融想搞明白什么因素是有效的,第一个直觉可能就是看loss曲线。当然我们希望loss平稳下降,对多数架构来说,loss和下游性能是相关的(参考Llama3技术报告,其中认为loss的负对数和下游性能成线性关系,个人认为这种相关性基于一个强假设:超大规模数据在各种类上的分布是接近的。)。但这并不全面:
- 以数据ablation为例,不同类型的数据loss就是会不一样(比如维基百科和网页数据),这时loss衡量的只是预测语料的难度,并不代表着loss越低性能越好;
- tokenizer改了之后、loss就没啥比较的意义;
- 某些特定能力上的强化(比如推理、数学)在平均loss上被抹平了;
- loss收敛之后模型还能在下游任务上接着improve。
细粒度的考虑评估的话,就用下游benchmark来评估(知识、理解、推理、其他重要的domain)吧。 挑benchmark要选能给明确的早期信号的,避开有噪声的。FineWeb的评估由以下四个原则决定:
- 单调性:模型训了分数得涨
- 低噪声:同样的设置+不同的随机数种子,得到的分数不应该有很大差异
- 高于随机的性能:比如选择题你说你能拿个20%的分数,还不如我在答题卡上踩一脚
- 排名一致:保序,一个方法早期更好,它就得一直好下去。
所以这几个原则实际上对评估的选择做出了很大的限制,评测的质量实际上和你的任务定义(怎么问模型问题)、指标计算(别老惦记exact match,评测真得多花功夫,不能糊弄)都相关,这个是需要注意的。
三种经典的任务是:选择题、完形填空题、自由生成。选择就类似MMLU直接exact match选项了;在完形填空里,作者会比较不同选项的似然;在自由生成里,直接看看贪婪生成的准确率。 但实际上消融属于训练不充分,这时候自由生成太难了,所以作者们主要关注了选择和完形填空。而到了后训练的时候就相反了,这时候自由生成会成为主要的评估。
许多工作指出早期训练的时候完形填空是个更好的信号。这里作者特别指出:他们计算完形填空准确率(百分之多少的标准答案有着最高的对数似然)时会用字符数做归一化,避免长答案和短答案的偏差。(在想这里是character合适还是token合适)
具体来说,作者们的评估包括如下(除了GSM8K, HumanEval, RULER之外(对于3B模型),benchmark都只用了1000个问题,以便加速。),所有的选择题benchmark作者们也用了上述提过的完形填空的方式去评估。:
| Benchmark | Domain | Task Type | Questions | What it Tests |
|---|---|---|---|---|
| MMLU | Knowledge | Multiple choice | 14k | Broad academic knowledge across 57 subjects |
| ARC | Science & reasoning | Multiple choice | 7k | Grade-school level science reasoning |
| HellaSwag | Commonsense reasoning | Multiple choice | 10k | Commonsense reasoning about everyday situations (narrative completion) |
| WinoGrande | Commonsense reasoning | Binary choice | 1.7k | Pronoun resolution requiring world knowledge |
| CommonSenseQA | Commonsense reasoning | Multiple choice | 1.1k | Commonsense reasoning about everyday concepts |
| OpenBookQA | Science | Multiple choice | 500 | Elementary science facts with reasoning |
| PIQA | Physical commonsense | Binary choice | 1.8k | Physical commonsense about everyday objects |
| GSM8K | Math | Free-form generation | 1.3k | Grade-school math word problems |
| HumanEval | Code | Free-form generation | 164 | Python function synthesis from docstrings |
怎么做数据混合的消融?控制变量
对于架构的消融,就是固定一个数据混合策略,这能很好的外推到其他数据集/领域上。 对于数据的消融,就是固定一个架构,然后改变数据混合策略
Estimating ablations cost
得考虑考虑你要在消融上花多少资源(GPU hours)。作者的实践作为参考(消融会超过主训练资源的一半,实际上可以几乎认为准备+调试的成本和正式训练一样多)
| Phase | GPUs | Days | GPU-hours |
|---|---|---|---|
| Main pretraining run | 384 | 30 | 276,480 |
| Ablations (pretraining) | 192 | 15 | 69,120 |
| Ablations (mid-training) | 192 | 10 | 46,080 |
| Training reset & debugging | 384/192 | 3/4 | 46,080 |
| Total cost | - | - | 437,760 |
作者们跑了100个左右的ablation,花了20天跑预训练的ablation,10天跑训练中的ablation,7天因为一个必须要debug+重跑的bug而重启训练。
Rules of engagement
TL;DR: Be paranoid
- 验证评估方案,在训模型之前先确保你的评估方案能复现已发布模型的结果。涉及到生成式的任务,要谨慎并且手动检查一些样本,确保prompt的格式没问题、任何后处理都能提取正确的信息。由于评估将指导接下来的决策,这一步非常重要。
- 不管多小的变化都要测试,别低估看上去没啥影响的库更新/小commit。
- 一次只改一点,变化之间会有联动,要独立的评估每个变化带来的影响。
- 吃充足的token、充分评估。不然结果是不可靠的。
1的确需要强调,我发现大家都会下意识低估评估这件事,觉得四处找几道题就完事了,这肯定是不行的。2和3属于软件开发的规范。4虽然很痛苦但也得做
预训练——Designing the model architecture
回到作者他们的情况,他们需要一个端侧应用的模型、需要有多语言支持、数学和编程能力、长上下文。所以他们选择了一个3B模型(可以轻松装进手机 当然我对此有点奇怪,他们大可以训个大的、然后量化部署在手机上,模型尺寸可以再大一倍以上),Dense架构 这么大的模型上MoE属于给自己找乐子,当然了A3B我觉得也不是不能接受,但作者们只有三个月,不足以尝试比较复杂的方案。
Architecture choices
基础肯定是Transformer,改来改去的都是核心组件(包括MoE)。改动的目的包括:推理时的内存限制、大规模的训练稳定性、长上下文处理。比如从MHA换到GQA这种已经广泛采用了,而位置编码之类的还有很多争论。可以看看现代领先的模型趋同于哪些选择:
| Model | Architecture | Parameters | Training Tokens | Attention | Context Length (final) | Position Encoding | Precision | Init (std) | Optimizer | Max LR | LR Schedule | Warmup Steps | Batch Size |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepSeek LLM 7B | Dense | 7B | 2T | GQA | 4K | RoPE | BF16 | 0.006 | AdamW | 4.2×10⁻⁴ | Multi-Step | 2K | 9.4M |
| DeepSeek LLM 67B | Dense | 67B | 2T | GQA | 4K | RoPE | BF16 | 0.006 | AdamW | 3.2×10⁻⁴ | Multi-Step | 2K | 18.9M |
| DeepSeek V2 | MoE | 236B (21B active) | 8.1T | MLA | 128K | Partial RoPE | - | 0.006 | AdamW | 2.4×10⁻⁴ | Multi-Step | 2K | 9.4M→37.7M (warmup 225B) |
| DeepSeek V3 | MoE | 671B (37B active) | 14.8T | MLA | 129K | Partial RoPE | FP8 | 0.006 | AdamW | 2.2×10⁻⁴ | Multi-Step + Cosine | 2K | 12.6M→62.9M (warmup 469B) |
| MiniMax-01 | MoE + Hybrid | 456B (45.9 active) | 11.4T | Linear attention + GQA | 4M | Partial RoPE | - | Xavier init with deepnorm scaling | AdamW | 2×10⁻⁴ | Multi-Step | 500 | 16M→32M→64M→128M |
| Kimi K2 | MoE | 1T (32B active) | 15.5T | MLA | 128K | Partial RoPE | BF16 | likely 0.006 | MuonClip | 2×10⁻⁴ | WSD | 500 | 67M |
| OLMo 2 7B | Dense | 7B | 5T | MHA | 4K | RoPE | BF16 | 0.02 | AdamW | 3×10⁻⁴ | Cosine | 2K | 4.2M |
| SmolLM3 | Dense | 3B | 11T | GQA | 128K | NoPE | BF16 | 0.02 | AdamW | 2×10⁻⁴ | WSD | 2K | 2.3M |
Attention
首先是MHA和GQA(注意力该有多少个头),简单来说,假如你有N个head,这个head会被用于计算query、并根据key检索value,推理时由于是自回归的,所以涉及大量的重复计算,可以将过去token的KV值作为缓存(KV-Cache),这个东西会随着上下文窗口的增长成为推理瓶颈,消耗大量GPU内存。
$$s_{KV} = 2\times n_{bytes}\times seq \times n_{layers} \times n_{heads}\times dim_{heads}$$虽然是线性增长,但也很恐怖了。
所以一个自然的想法是:并不是每个head都有必要。MQA和GQA用于解决这个问题。GQA就是试着让一组head共用KV值。
顺带一提,下文代码是我面试时搓GQA的代码,可以清晰看到其和MHA的区别
|
|
而Deepseek的MLA是另一种策略:对KV Cache进行压缩,压缩为一个latent变量。
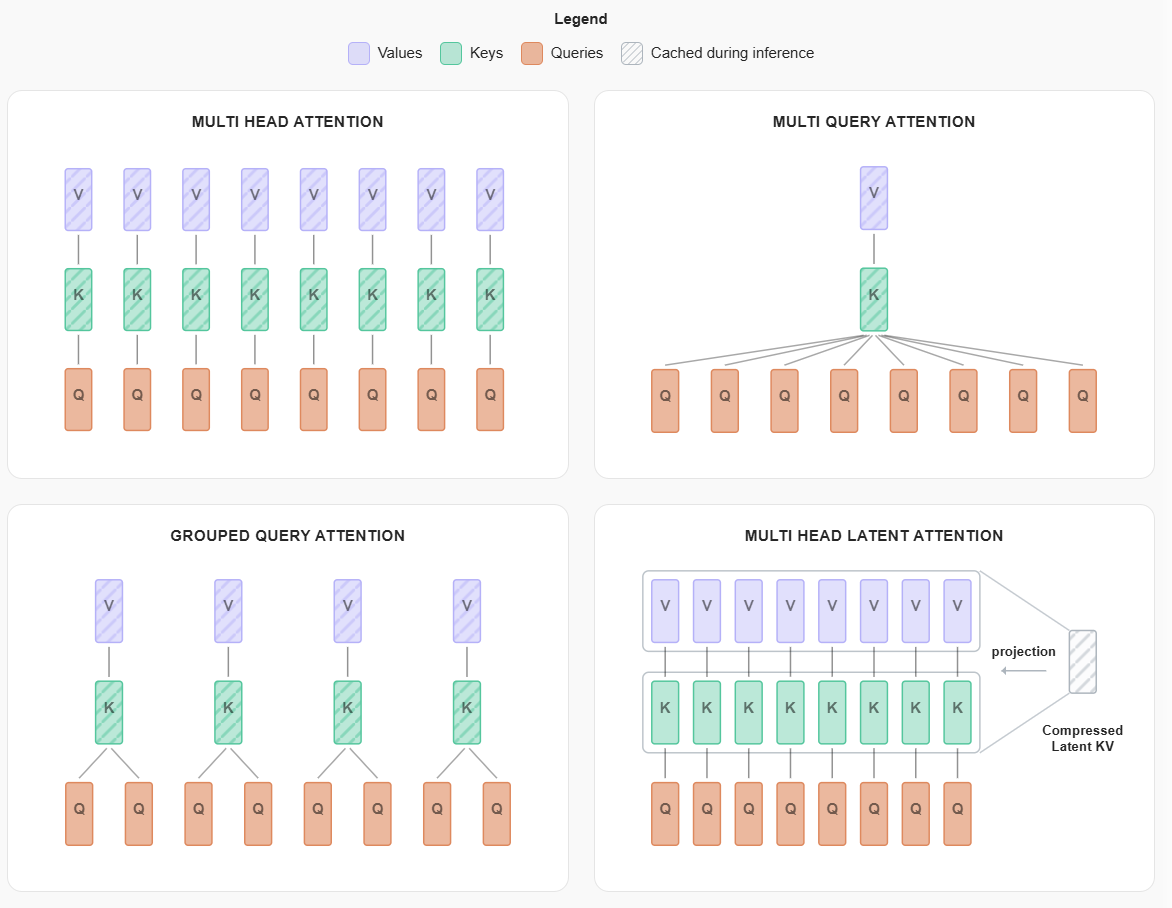
作者做了一些消融对比实验,图比较多我就不抄了,记一下几个结论和现象:
- KV head太少甚至直接退化到MQA,效果明显很差。如果group大小只是2、4、8(也即num_head/kv_head),效果大致与MHA相当。
- group=8时训练早期有一个比较奇怪的拐点,暂时不知道是为什么
值得一提的是,最近的minimax m2从Linear Attention改回了Full Attention,他们的技术报告中提到,他们尝试了多种Linear Attention的变体,发现随着上下文的拉长,这些性能都会大幅下降。他们提到一部分问题出在评估不好、在当前的评估上Linear Attention和Full Attention拉不开差距。所以针对这里group=8时也和group=2、MHA拉不开差距,可能有一部分因素出在这里
Document Masking
怎么在训练时应用注意力(也即文档掩码和dataloader怎么构建)。
-
padding的问题:短文档占多数(2k以下的文档在CC和GitHub中占80~90%),这些短文档是填不满序列长度的。总不能全部pad到目标长度,太浪费了。所以一般是多个文档拼起来(packaging),用EOS token做区分,然后根据序列长度切块分割。
-
但这样会引入一个新的问题:不同文档是不相关的,放一起就是纯噪声。所以有人时使用了intra-document masking,让token只对同一个文档计算注意力(因果)。这样也能让长文里的注意力更集中。llama3也干了,发现这对短上下文影响有限、长上下文很明显的好处。
当然,作者们也针对要不要引入intra doc masking这个问题做了一下消融:
- 对于短上下文:在WinoGrande、PIQA上引入更好(+0.5%~1%,目测),在ARC上引入反而更差(-~0.5%,目测),在别的benchmark和预训练loss上效果不显著。那其实就是看不出区别。
- 对于长上下文:当训练后期扩展到长上下文时(训练中后期),intra doc masking会非常重要。作者们从4k扩展到了64k,详情写在marathon这一章。
这里补一句前置知识,预训练阶段的上下文长度上限不是固定不变的,归根结底是在算力约束下,大家想尽可能拓展到长上下文。一般会分三个阶段:1. warmup:初始化阶段,吃的token少,长度会很短,比如4096~8192;2. pretrain:预训练的主要阶段,这一阶段长度会逐步扩大,以llama3为例,分了六个小阶段,从8192逐步扩展到了128k3. annealing:最后的退火,用少量高质量数据、最长的上下文(比如128k)
Embedding
这里主要的问题就是要不要tied embedding层,也就是要不要让输入的token->embedding的矩阵和输出的embedding->token的矩阵共享权重。这对于小模型来说是一个必要的选择。因为假如你hidden dim选择2048(8B模型没有用这么小的hidden dim),vocab size到128k左右(多语言的话很难再小了),那一个输入的embedding矩阵就要占差不多0.26B参数了,不tied就再翻个倍,你的1B模型有一半是输入输出的线性层,那很朋克了。
而对于大点的模型,一般没必要这么做,参数够多。不过这一点依然是值得做消融的。作者做了,结论是:
- 如果参数量就那么大(不tied的对比模型层数会少4层),那对于小模型来说就得tied
- 如果其他非embedding的参数不变,tied与不tied(意味着后者的参数量会比前者多一个线性层)两者依然是差不多的,甚至tied的loss更低一点,性能在多数benchmark上好一点。
所以参数预算不变的情况下,不如把embedding tied了,省点权重给网络加几层,普遍还是认为网络深度与推理能力是正相关的。
Positional Encodings
transformer天然的问题是注意力是并行的,感知不到词序。所以解决方案是人为的给每个token添加一个标记其绝对位置(或相对位置)的编码。
早期的sinusoidal位置编码是绝对位置编码,将每个位置映射到一个向量,然后加到token embedding上。这对短序列效果很好,但绝对位置编码不支持外推。
正如前面所说,外推的意义在于,计算量和序列长度的平方是成正比的,算力限制我们不能直接在超级长上下文上直接训练。
所以后来转到相对位置编码,比如AliBi(根据token距离修改attention score)。以及现在主流的RoPE(将位置编码为一个旋转,token之间的距离用旋转角度来描述),值得一提的是,RoPE不会像sinusoidal一样直接把position embedding加在token embedding上,而是给所有Attention块的输出加一个旋转。
我整理了一下公式,假设dim是偶数且等于2n:
$$x_{pos} = [x_1, x_2, \cdots, x_{2n-1}, x_{2n}]\\ \Rightarrow\\ [x_1\times\cos{t_1}-x_2\times\sin{t_1}, x_1\times\sin{t_0}=x_2\times\cos{t_1},\cdots, x_{2n-1}\times\cos{t_n}-x_{2n}\times\sin{t_n}, x_{2n-1}\times\cos{t_n}-x_{2n}\times\sin{t_n}] \\ \text{where}\quad t_k = \frac{pos}{\text{base}^{2k / dim}}$$也就是说,给位置pos的向量,每两个相邻的维度进行一次旋转,这样的话位置pos_1和pos_2之间的两个向量注意力的模式可以只考虑相位差,这种基于距离的模式和绝对位置是无关的。可以参考原作者苏剑林的博客
RoPE频率
这个基频(也就是base)会有两个影响: 1. 设的太小,t_k对于快到序列末尾的token来说,可能都转了不知道多少圈了,可能会导致注意力分数衰减过快2. 设得太大,相位差又都太小了体现不出特别大的差别。
所以解决方案是随着序列长度的增加而增加基频。比如RoPE ABF (RoPE with Adjusted Base Frequency)、YaRN (Yet another RoPE extensioN) 。不赘述了。
现在主流的大模型全用的RoPE,Qwen、Gemma、Llama等等。
如果上下文更长,那RoPE性能也不行了。大海捞针benchmark里表现都不佳就是例证。
所以有人认为不需要一个明确的位置编码:
比如NoPE,让模型从因果mask里隐式的学习位置信息,但实践上这样在短上下文和知识型的任务里表现就比较差。
或者有人把RoPE和NoPE混起来(交替使用),算是trade off。比如Llama4(详细怎么混的我记得以前见过,但这次没找到,记不清是2+1还是3+1了,主打的大海捞针,实际性能也很微妙)。
Partial RoPE:也有人只在模型的部分维度上使用RoPE,比如GLM-4.5和Minimax-01是这么干的,作者称所有用MLA的模型都会因为限制推理消耗而使用这种策略。我完全没见过这种做法,有空看看
所以到消融,这个地方作者们比较了3+1的NoPE(即3层RoPE+1层NoPE)、RoPE、以及NoPE+doc mask。在短文本上性能没啥区别,所以作者们使用了NoPE+doc mask。
总结一下关于Positional Embedding的内容:
- 用RoPE
- 部分层用RoPE,其他层不用位置编码
- 部分维度用RoPE,其他维度不用位置编码
- 调整RoPE的基频
实际上还有种保序/限制注意力的思路可以和Positional Embedding结合:限制token之间的注意力,比如说分块、或者加窗。llama4就是这么干的(分块),只在一个块内互相计算注意力(3+1,其中用NoPE的1不分块,用RoPE的3分8192大小的块,这样做感觉很蠢,块间的关系都被破坏了)。Mistral 7B选择加窗(滑动窗口),每个token只能看到最近的N个token(完全这么干,长上下文就烂了),Gemma 3把滑动窗口和不用滑动窗口的层结合起来交替使用,就跟前面RoPE+NoPE混着用一样。
这里会出现一个比较有意思的现象:Attention Sink(也即模型对序列中的前几个token产生异常高的Attention score),哪怕这些token语义上没啥用,作者认为这些初始token会成为用于稳定注意力分布的“锚”。实践上对此的利用是:在计算KV Cache的时候只保留最初几个token的KV Cache,以及最近几个token的滑动窗口,这样能在上下文超过Cache上限的时候很大程度上恢复性能。
Stablity
不稳定性是个大问题,实际上不会有绝对稳定的模型训练方法,尤其是模型大了、数据多了,总会有概率事件发生。
这里指的不稳定主要是:loss飞了(spikes)、loss跳了(jumps)
几种方法包括:
Z-loss
正则化,给Loss函数加一个惩罚项:
$$\mathcal{L}_{z-loss} = \lambda\cdot\log^2(Z)$$作者们的消融实验显示:Z-loss不会影响性能。但作者们也没用Z-loss,因为Z-loss引入了额外的训练开销(不太懂他们的实现是怎么搞的)
把weight decay从embedding中移除
weight decay一般是所有参数都会用的正则化技术,但OLMo发现不给embedding层应用weight decay会提高训练稳定性(因为weight decay导致embedding的norm在训练期间减小,导致前面几层梯度更大)。
所以作者做了消融实验:
- No WD + NoPE + doc mask
- No WD
- WD
发现这三种改动也都不会影响性能。所以最后作者们用了No WD + NoPE + doc mask
QK-norm
在计算 Attention score 之前对query和key做一遍layer norm。能防止attention的logits太大,所以近来很多模型都在用。
但也有人发现QK-norm对长上下文任务有害(毕竟抹平了,上下文一长,注意力就没法那么集中了)。他们认为norm消除了QK dot product里的幅度信息,让logits的幅度更接近了。所以作者们没用。
Other
除了上面提过的东西,还有一些架构上的决策:
- 参数初始化策略:一般会用truncated normal initialization(N(0, 0.02))或者muP
- 激活函数:一般用SwiGLU
- layout:一般认为,在语言建模和组合的任务上,更深的模型更好;而更宽的模型推理更快(因为能并行更多)
Sparse: MoE
MoE的直觉在于:每次预测不需要完整的模型,就像大脑会根据不同任务激活不同的区域一样。这样可以节省计算(每次推理只激活一部分参数)
在技术上,MoE的目标是:不改变每个token的激活参数数量(即推理成本),而增加总参数(能力上限)。
一般来说的做法会是:把Transformer里的大MLP变成由一个可学习的gate层(或者叫router)连接的多个小MLP(experts)。
那么就有几个核心问题了:
- expert shape和稀疏性:你该用多大的experts?每个token要激活多少个experts?要不要有一些一直处于激活状态的experts(即universal)?
- 利用率的问题:怎么避免空转,选择experts并让它们被充分利用。
目标:给定计算量。怎么选择能让loss最小的MoE配置。这在蚂蚁的MoE scaling law里有记载。
所以用一个EL(Efficiency Leverage)作为指标,这个指标衡量了要达到MoE架构的loss,你需要多大的dense计算量(单位FLOPS)。越高的EL意味着单位计算量下MoE比dense改善了越多的loss。
这里放了一个Loss Scaling Curve,简单描述一下就是同样的计算量下(从1e19到1e25),MoE的Loss可以稳定比Dense低0.2左右(几乎是两条平行的曲线)。
所以关于怎么设定MoE,考虑稀疏/激活比例
TL;DR:更高的稀疏 -> 更好的FLOPS效率 -> 在很高的稀疏下收益递减 -> 根据你的算力得到最优点
简而言之,两个极端(全激活/几乎全都不激活)都不可取,得在中间找个trade off。首先定义一下两个量:
$$\text{activation ratio} = \frac{\text{\#activated experts}}{\text{\#total experts}}\\ \text{sparsity} = \frac{\text{\#total experts}}{\text{\#activated experts}} = \frac1{\text{activation ratio}}$$算力来说,完全是由active参数决定的;所以如果你增大experts的总数而固定activated experts数量(及尺寸),推理/训练成本大致不变,而模型容量及性能上限就高了(这个地方有点阔绰了,对于还没富裕到可以忽视显存只考虑FLOPS的团队来说,显存也是成本及限制之一)。最近也有一些工作的核心思路是这样,loss低了,模型的稀疏性也越来越高。
Kimi k2和蚂蚁都有类似的结论:稀疏性越高、表现越好,但收益是逐渐降低的,高稀疏性主要是考虑对算力有利。
一些MoE模型的稀疏性配置(我给这个表加了个大概的发布时间,在huggingface上查的,可能由于修改等原因导致和最早的发布时间不一样,比如Qwen3):
| Model | Total experts | Activated per token (incl. shared) | Sparsity | Pub. Time |
|---|---|---|---|---|
| Mixtral-8×7B | 8 | 2 | 4.0 | Dec. 2023 |
| Grok-1 | 8 | 2 | 4.0 | Mar. 2024 |
| Grok-2 | 8 | 2 | 4.0 | Aug. 2025 |
| OLMoE-1B-7B-0924 | 64 | 8 | 8.0 | Aug. 2024 |
| gpt-oss 20b | 32 | 4 | 8 | Aug. 2025 |
| Step-3 | 48 routed + 1 shared = 49 | 3 routed + 1 shared = 4 | 12.25 | Aug. 2025 |
| GLM-4.5-Air | 128 routed + 1 shared = 129 | 8 routed + 1 shared = 9 | 14.3 | Jul. 2025 |
| Qwen3-30B-A3B | 128 | 8 | 16.0 | Jul. 2025 |
| Qwen3-235B-A22B | 128 | 8 | 16.0 | Jul. 2025 |
| GLM-4.5 | 160 routed + 1 shared = 161 | 8 routed + 1 shared = 9 | 17.8 | Jul. 2025 |
| DeepSeek-V2 | 160 routed + 2 shared = 162 | 6 routed + 2 shared = 8 | 20.25 | May. 2024 |
| DeepSeek-V3 | 256 routed + 1 shared = 257 | 8 routed + 1 shared = 9 | 28.6 | Dec. 2024 |
| gpt-oss 120b | 128 | 4 | 32 | Aug. 2025 |
| Kimi K2 | 384 routed + 1 shared = 385 | 8 routed + 1 shared = 9 | 42.8 | Jul. 2025 |
| Qwen3-Next-80B-A3B-Instruct | 512 routed + 1 shared = 513 | 10 total active + 1 shared = 11 | 46.6 | Sep. 2025 |
趋势很明显:稀疏性逐渐上升(这些模型选的完全看不出什么趋势)。稀疏性没那么高的主要是由于硬件限制(包括带宽),比如Step3等模型就没有很大的稀疏性,GPT-OSS 20B设定是端侧模型所以也没有很稀疏,这个和120B对比起来能很明显看出来。
粒度(Granularity)
除了稀疏性之外,还得考虑每个expert的大小。粒度 $G=\frac{\alpha*d_{model}}{d_{expert}}\quad\alpha=2\ or\ 4$
在dense model里,一般来说intermediate dimension会取到 hidden size 的4倍(4倍最早是Transformer的设置,实际上现在一般dense模型会取比4倍小一些的值,可能是消融做出来的结果),所以如果 $\alpha=4$,你可以大概看到粒度G就是需要多少个expert能和dense MLP的宽度一样。
粒度对EL的影响没那么主要,不过的确存在一个trade off点,粒度越高收益越平缓。同样的下面有个表:
| Model | (dmodel) | (dexpert) | (G=2dmodel/dexpert) | Year |
|---|---|---|---|---|
| Mixtral-8×7B | 4,096 | 14,336 | 0.571 | 2023 |
| gpt-oss-120b | 2880 | 2880 | 0.5 | 2025 |
| gpt-oss-20b | 2880 | 2880 | 0.5 | 2025 |
| Grok 2 | 8,192 | 16,384 | 1.0 | 2024 |
| StepFun Step-3 | 7,168 | 5,120 | 2.8 | 2025 |
| OLMoE-1B-7B | 2,048 | 1,024 | 4.0 | 2025 |
| Qwen3-30B-A3B | 2,048 | 768 | 5.3 | 2025 |
| Qwen3-235B-A22B | 4,096 | 1,536 | 5.3 | 2025 |
| GLM-4.5-Air | 4,096 | 1,408 | 5.8 | 2025 |
| DeepSeek V2 | 5,120 | 1,536 | 6.6 | 2024 |
| GLM-4.5 | 5,120 | 1,536 | 6.6 | 2025 |
| Kimi K2 | 7,168 | 2,048 | 7.0 | 2025 |
| DeepSeek V3 | 7168 | 2048 | 7.0 | 2024 |
| Qwen3-Next-80B-A3B | 2048 | 512 | 8.0 | 2025 |
Shared Experts
始终激活的expert叫 shared expert。这些shared expert主要(被期望)用于学习数据中基础的、重复出现的模式,这样其他expert能更专业一点。实践上,不需要很多shared experts,一般一两个。随着粒度增加,shared expert就更有用。一般来说有个经验结论:只用一个shared expert。这样复杂度不会不必要的增加、计算效率也能最大。
Load balancing
MoE里既然涉及router和experts,负载均衡就是关键部分。想象一下四张卡各放一个expert,如果负载均衡寄了,绝大多数token都被路由到expert 1,那四分之三的卡就在空转。而且其他三个专家得不到训练。
所以可以给router加一个额外的Loss项:
$$\mathcal{L}_{Bal}=\alpha\sum_{i=1}^{N_r}f_iP_i$$其中fi是流量划分(所以只有这一部分的token会过expert i),与实际均衡相关。Pi是概率质量(对所有过这个expert的token的概率总和),主要是在算梯度的时候平滑、可微分。最完美的情况下,f和P都是N分之一,这里就只剩一个超参alpha。这个额外的loss太大会影响模型性能;太小起不到效果,就看怎么调了。
Deepseek V3介绍了一种无损的负载均衡:在router的softmax里引入了一个偏置项,如果一些experts过载了就降低score,否则增加。
这个公式很简单,如下:
$$g'_{i,t} = \begin{cases}s_{i,t},& s_{i,t}+b_i\in\text{Topk}(\{s_{j,t}+b_j|1\leq j\leq N_r\}, K_r)\\0,&\text{otherwise}\end{cases}$$g是用于乘在FFN输出前面的,简单来说,就是通过给每一个expert一个偏置项b,这个b会在每一步结束的时候更新(如果使用了这个expert就减小$\gamma$,否则增加$\gamma$),然后用s+b的总和来选取expert(一个expert的分数越高、越久没有被选择,就越容易被选择)
那这里其实会有一个问题:f和P是按local batch(每个device的mini batch)计算还是global(所有device的global batch)计算?Qwen团队的结论是:local batch可能会因为token的多样性不足而损害性能(expert与特定领域的相关性;以及模型整体性能),所以应该尽量使用global。值得一提的是:截至这篇文章写出来,许多框架(包括Megatron)还是会在本地计算这两个参数。
一般来说,MoE架构的ablation会因为许多问题的相互作用而很棘手。
We have now covered the fundamentals of MoEs, however there is still more to discover. A non-exhaustive list of items to further study:
- Zero-computation experts, MoE layer rescaling and training monitoring (LongCat-Flash paper).
- Orthogonal loss load balancing (as in ERNIE 4.5).
- Scheduling the load-balancing coefficient over training.
- Architecture/optimization interactions with MoE, like:
- Whether optimizer rankings change for MoE.
- How to apply MuP to MoE.
- How to adapt the learning rate for MoE (since they don’t see the same number of token per batch).
- Number of dense layers at the start.
我对MoE没啥实操经验所以上面的问题没什么看法,很遗憾。接下来会想办法训点MoE模型的。
Excursion: Hybrid
最近的一个趋势是用SSM(状态空间模型)或线性注意力增强模型。主要是因为Transformer的固有缺点:N^2复杂度,处理不了超长上下文。混合模型指的就是先行注意力和标准注意力的混合。
线性注意力相关的工作一直以来都不少,也有一些基于Attention块高度稀疏的特征试着做压缩的。不过在这方面的工作大多只在小模型上做了验证,除了最新的Qwen3-Next(80B-A3B依然不知该算小还是大,和30B-A3B坐一桌吧先)。在线性注意力像MoE一样得到工业界的实践验证、变成一个工程问题之前(指一个超大杯的、性能第一梯队的开源模型),我暂时对这个学术问题不感兴趣。跳过了。
recall到前面GQA时我写的内容:> 值得一提的是,最近的minimax m2从Linear Attention改回了Full Attention,他们的技术报告中提到,他们尝试了多种Linear Attention的变体,发现随着上下文的拉长,这些性能都会大幅下降。他们提到一部分问题出在评估不好、在当前的评估上Linear Attention和Full Attention拉不开差距。所以针对这里group=8时也和group=2、MHA拉不开差距,可能有一部分因素出在这里这显然是对线性注意力的一大利空(笑)
MoE or not MoE
现在主要的模型架构看了一圈,问题就在于怎么选了。主要取决于:
- 你要在哪儿部署?端侧(主要指手机、嵌入式设备吧)、消费级显卡(比如5090之类的)、集群
- 你的团队水平怎么样?我建议水平一般就选dense,否则MoE,会看到这句话的人不建议选hybrid笑
- 你的timeline?越紧急意味着你应该选择越简单、经过越多人验证的架构,比如dense
tokenizer
虽然不怎么起眼,但这是模型中最被低估的组件之一(我完全同意,没有之一)。
简单描述一下现代模型的分词,因为大家可能没怎么注意过:首先会用正则过一遍pre-tokenization,目的是根据空格、换行、数字、符号等等把词自然的切分开;然后用BPE之类的算法找出现最频繁的子词对合并;然后就得到了一个tokenizer。
我个人总结一下我对tokenizer的几个核心认知:1. 训tokenizer的数据分布不能和训模型的数据在分布上有很大差别,比如说你想在一个英语预训练模型上训中文能力,那效果会很差,至少也得考虑扩展词表。代码、数学等等一样,这方面有很多论文就不再赘述。2. 压缩率很重要,在训tokenizer的算法是BPE的前提下,词表越大压缩率越大,然而embedding层也就越大。这里作者推荐:单语言用50k,多语言100k以上,和我的认知是一致的(64k & 128k)。有很多工作分析了压缩率和下游性能的关系,通常认为压缩率越高性能越好,我认为这个结论有很大的问题,但压缩率和下游性能肯定是显著相关的。同时,压缩率越高意味着同样的句子用了越少的token,因而训练推理成本是低的3. 主流模型对tokenizer的做法还都很粗糙,所以如果你正在训一个domain-specific的模型,不妨思考一下什么样的tokenizer更适配你的任务。有工作的结论是:哪怕你换了个新的tokenizer,那么原有的embedding层也会是一个很好的初始化,具体的初始化策略可以搜索“tokenizer transfer”或者“initialization”之类的。4. 也不一定要在基于BPE的tokenizer这棵树上吊死,可以看看最近的一些新工作,包括Meta的Byte-Latent-Transformer、Deepseek-OCR、最近清华的CALM等
目前最流行的选择依然是BPE算法,这里就有一个决策:应该用现有的tokenizer还是从头开始训?应当取决于coverage:现有的tokenizer能不能cover你的目标语言/领域,并且词表大小和你预想的差不多。
要衡量一个tokenizer的质量,有以下两个指标,这两个指标都是越低越好:
- Fertility:平均编码一个word需要的token数,与我上面说的压缩率的不同之处在于:我说的压缩率是针对character,而这里是word
- Proportion of continued words:百分之多少的word被切分了。这个比例越低越好。
|
|
对于特定的比如代码、数学等领域,需要更深入研究tokenizer。大多数现代tokenizer会把数字按digit切分,“123” -> [“1”, “2”, “3”](实际上也有很多工作每三个digit切一次)。这实际上有助于模型学习算术问题的模式。
要比较不同语言上的tokenizer,可以用wikipedia的文章作为语料。细节不再详述。
关键的问题还是在于:选已有的tokenizer还是自定义的?
- 如果你的目标任务和最好的分词器(Llama、Qwen等)的语言/领域覆盖范围是匹配的,那就直接用。作者的SmolLM3是直接用了Llama3的tokenizer。
- 如果你的目标语言是低资源语言,或者数据混合比例非常不一样。那可能得自己训。
当然,以我的认知来说,tokenizer和embedding层是绑定的,一直有一些文章(上面也提到过)试着在这个迁移的过程中减少工作量,但无论如何想改动tokenizer而不改动embedding层是不可能的。自己训这个选项可以从merges.txt出发,简化一些工作量;而embedding层的初始化可以学习这些论文的做法,减少工作量。
SmolLM3
Rules of Engagement
TL;DR:需要啥再用啥,别为了用而用。糙话
Optimizer and training hyperparameters
Optimizers: AdamW and beyond
Learning Rate
Batch size
Scaling laws for hyperparams
SmolLM3
Rules of Engagement
Scaling laws: how many params and data
预训练——The Art of Data Curation
预训练——The training Marathon
后训练——Beyond base models – Post training in 2025
graph TD A([Base model]) --> B([SFT]) & C([ORPO]) & D([DPO and friends]) & E([RL here be dragons]) & F([KTO]) C <-.-> E D <-.-> F
后训练包括SFT(有监督微调)、RL(强化学习)等等。
Post-Training compass: why -> what -> how
和之前一样,首先是why:
- 你真的需要后训练吗?开源模型在很多任务上已经很强了,你需要一个通用助手的话,先看看现成的开源模型够不够用。
- 你有高质量的、领域内的数据吗?如果通用模型在你的任务/领域上表现不好,那你是否有正确的数据(尤其是高质量!)
- 你能衡量成功与否吗?也就是明确的评估标准。别说“我看输出它训完好了很多”这种鬼话
然后是what,你要什么决定了你怎么做:
- 你要一个不会偏题的、简洁的指令执行者吗?
- 你要一个按需切换语调和职责的多功能助手吗?
- 你要一个能处理数学代码或者agentic问题的推理引擎吗?
- 多语言?
最后是how:
- SFT:灌输核心能力
- PO(Preference Optimisation):直接从人类或AI偏好中学习(稍等这个不应该是RL的子集:PPO/DPO吗?)
- RL(Reinforcement Learning):超越监督数据的可靠性和推理能力
- Data curation:多样性和质量之间的平衡
- Evaluation:评估进步
看看作者们SmolLM3的答案:
- Why?有一个base模型,在发布之前得做后训练。同时,也是为了开源混合推理模型的训练配方(类似Qwen3),贡献一个跟Qwen3的1.7B/4B一块站在帕累托前沿的recipe。
- What?混合推理模型;推理能力、除了英语以外的其他语言;工具调用和长上下文(虽然这个模型的上下文并不特别长,64k处于一个比较微妙的地位)
- How?接下来会讲。
后训练和预训练阶段的评估消融几乎一样,除了一个关键区别:这里的消融应当在“更小的数据集、更简单的算法”上做。
First things first: evals before everything else
完全赞同,首先确定需求场景->任务->评估,再琢磨数据、方法、超参的问题
- 评估得新:数据泄露是不可避免的,预训练时见过的benchmark就不适合作为评估,所以评估得持续更新。而且也是为了更好地适应需求(需求一直在微调)
- 能力评估:
- knowledge:比如GPQA(还没饱和,比MMLU更合适)、SimpleQA(小模型可能表现不好)
- math:AIME、Math-500(虽然推理模型都饱和了),如果要更全面,就用MathArena
- code:LiveCodeBench(这上面的改进的确能转换成编程能力,但仅限python)。SWE-bench Verified更复杂,但对小模型太难了。
- multilinguality:这方面没啥选择,Global MMLU、MGSM等。
- 综合任务评估:
- Long context:大海捞针(NIAH)但是有点浅、RULER、HELMET、MRCR和GraphWalks难度更高。
- Instruction following:IFEval、IFBench、Multi-IF和Multi-Challenge(多轮)
- Alignment:模型和用户意图的对齐,太自由了,所以要么人标注、要么LMArena
- Tool Calling:BFCL(饱和了)、TAU Bench
- 过拟合评估:GSMPlus(苹果的工作,我有印象是因为它以一种我鄙视的方式做了我想做的事)
- 内部评估:一些内部测试集,不多说
- Vibe评估和Arena:*Vibe这个b词太sb了,不如直接改名叫“道”吧,毕竟Vibe coding已经脱离技的范畴,进入“玄之又玄,众妙之门”的境界了。包括context engineering,我是真的很鄙视
大佬名字的这种行为,能不能实际一点,别老在旧词能覆盖的范围内造一些新词。或者先去接受一些哲学训练,确保自己对自己提出的概念足够清楚。作者这里的意思我认为是上面吐槽的“我看输出好多了”,或者像是发现Deepseek-R1-0527喜欢输出“极”这种问题,都是benchmark覆盖不了、需要人去捕捉的怪异行为。*但这个只适合作为低信号反馈。
但是:用开源benchmark的一大问题就是:容易数据泄露、过拟合。尤其是你合成数据来干的时候。所以你需要Decontaminate数据,尽量减少数据泄露。比如用N-gram匹配(Open-R1中有脚本)
作者建议优先考虑评估,尤其是要在整个后训练中保留哪些预训练的核心评估等等问题。
Rules of Engagement
- 用小的评估子集来加速评估
- 对于推理模型,把思维链从评分输出中去掉
- 如果用到了LLM judge,把作为judge的模型及其版本固定下来
- base模型的contamination问题,数据污染需要严格排除
- 如果可能,把所有消融实验中的东西都作为验证集,而不是测试集(最终保留一组没见过的benchmark)
- 始终保留一小部分vibe eval(如果是我,会写成“始终自己测几个case做一下case study”)
- 数量比较少的benchmark(比如2k条),要采样k次并且算
avg@k - 用一个新的eval的时候,确保你能复现几个模型已发表的结果
- 有疑问的时候就回去看评测数据,尤其是用来prompt模型的内容
Tools of the trade
| Framework | SFT | PO | RL | Multi-modal | FullFT | LoRA | Distributed |
|---|---|---|---|---|---|---|---|
| TRL | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Axolotl | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| OpenInstruct | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
| Unsloth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| vERL | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Prime RL | ✅ | ❌ | ✅ | ❌ | ✅ | ✅ | ✅ |
| PipelineRL | ❌ | ❌ | ✅ | ❌ | ✅ | ✅ | ✅ |
| ART | ❌ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ |
| TorchForge | ✅ | ❌ | ✅ | ❌ | ✅ | ❌ | ✅ |
| NemoRL | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ✅ |
| OpenRLHF | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
呃呃不支持Distributed的真能叫训练框架吗?这不纯垃圾吗?自己玩去吧
作者用TRL,我个人只读过TRL和一些transformers trainer套壳框架的源码,不过感觉大家都在用vERL,不知为何。
为什么要用框架:
… can that same script scale from 1B to 100B+ parameters?
Frameworks exist precisely because the basics are already well-understood and endlessly reinventing them is a poor use of time. That’s not to say there’s no value in low-level tinkering. Implementing PPO from scratch once is an excellent learning exercise. Writing a toy transformer without a framework teaches you how attention really works. But in most cases, just pick a framework you like and hack it for your purposes.
Why every post-training pipeline starts with SFT
- SFT需要的计算资源更少
- SFT很稳定:不像RL对Reward设计和超参数很敏感
- SFT是一个没什么毛病的baseline,能提供大多数收益,并且能让DPO、RLHF(指PPO吗?)之类的更有效
那deepseek-R1-Zero呢?
At the frontier, the usual reasons for starting with SFT don’t always apply. There’s no stronger model to distill from and human annotations are too noisy for complex behaviors like long chain-of-thought. That’s why DeepSeek skipped SFT and went straight to RL with R1-Zero; to discover reasoning behaviors that couldn’t be taught with standard supervision.
If you’re in that regime, starting with RL can make sense. But if you’re operating there … you probably aren’t reading this blog post anyway 😀.我笑了
Picking a base model
选完框架就该选base model了。 取决于:
- 模型大小:越大越好、而且越大需要的数据越少(泛化更好)
- 架构(MoE还是dense):MoE不好训但适合大规模、dense在较小规模上更好
- 后训练的记录(社区有没有别人在这个base模型上训过,如果有一堆很强的后训练模型,那这个base模型会是一个很好的选择)
暂时放个占位符,稍后我会放一个显存计算公式在这里
Training simple baselines
选完base model就该训个SFT baseline了。 一个好的baseline应该训起来很快,专注于核心能力,并且在特定能力不达标的时候能用更多数据扩展。作者们一开始用了WebInstruct做SFT,然后在vibe test的时候感觉它过于集中在科学能力上。所以后来创造了Everyday Conversations。
混合推理模型,主要针对推理、指令跟随和可控性:
| Dataset | Reasoning mode | # examples | % of examples | # tokens (M) | % of tokens | Avg. # tokens per example | Avg. # tokens in context | Avg. # tokens in response | Avg. # turns |
|---|---|---|---|---|---|---|---|---|---|
| Everyday Conversations | /no_think | 2,260 | 2.3 | 0.6 | 0.8 | 260.2 | 222.3 | 94.0 | 7.8 |
| SystemChats 30k | /no_think | 33,997 | 35.2 | 21.5 | 28.2 | 631.9 | 422.8 | 267.7 | 6.3 |
| Tulu 3 SFT Personas IF | /no_think | 29,970 | 31.0 | 13.3 | 17.5 | 444.5 | 119.8 | 380.7 | 2 |
| Everyday Conversations (Qwen3-32B) | /think | 2,057 | 2.1 | 3.1 | 4.1 | 1,522.4 | 376.8 | 1,385.6 | 4 |
| SystemChats 30k (Qwen3-32B) | /think | 27,436 | 28.4 | 29.4 | 38.6 | 1070.8 | 84.6 | 1,042.7 | 2 |
| s1k-1.1 | /think | 835 | 0.9 | 8.2 | 10.8 | 8,859.3 | 370.9 | 9,728.5 | 2 |
| Total | - | 96,555 | 100.0 | 76.1 | 100.0 | 2,131.5 | 266.2 | 2,149.9 | 4.0 |
作者们提到:训一个混合推理模型比标准的SFT更难,因为不能只是把数据集混合在一起,而是得琢磨不同模式的配比。理想的情况下,需要有平行的例子教会它什么时候切换模式。
以及,参考上表,考虑数据混合比例的时候是从token而不是sample的层面来考虑的。以及这里引入了一个挑战:每个数据集都得采取不同形式的格式化(支持thinking或者不支持),要想统一这些格式,就得有一个一致的chat template。
Picking a good chat template
如果你是从某个推理模型开始进行后训练,那个人认为原有的chat template对大多数场景已经够用了,几乎不需要考虑修改chat template的问题,除非你有一些非常独特的用途。
这个没有标准答案,实践中有几个需要考虑的问题:
- 用户可以自定义system role吗?(比如“act like a pirate”)
- 模型需要工具调用吗?如果需要模型调用API,那需要适配工具调用和响应的格式化输出。
- 是推理模型吗?推理模型会使用
… 的模板分割模型的“思考过程”和最终答案。有的模型在多轮对话中会丢弃think token。 - 能和推理引擎(inference engine)配合吗?比如vLLM和SGLang,有专门用于reasoning和tools的解析器,最好和这些解析器兼容。
大多数情况下,作者们认为ChatML和Qwen的chat template是一个很好的起点。作者们对于Qwen的唯一不满之处在于多轮对话中,除了最后一轮之外的reasoning内容都会被丢弃(主要是基于压缩上下文的考虑)。这也和OpenAI的工作方式类似。所以作者们自己打造了一个chat template。
此处作者们给出了一个playground,可以调试chat template:chat-template-playground
Baby Baselines
先搞点Baby Baseline,目的是做验证(你的chat template、超参等能否支持稳定训练),有了这个Baseline之后再考虑超参、数据配比和SOTA。
主要是以下几点:
- 要全参数SFT还是LoRA/QLoRA?可以查看thinking-machines-blog这篇博客,里面说特定条件下LoRA是能匹敌全参SFT的(通常由数据集大小决定)。关于这个博客我也读过,我LoRA无悔
- 哪种并行?对于小模型/LoRA,一般数据并行就够了。对于较大的模型,你需要FSDP2或者Deepspeed Zero-3来共享模型权重和优化器状态(还有梯度)。对于长上下文,也可以上下文并行(个人认为是序列并行的一种)
- 如果硬件支持,用类似FlashAttention或者Liger的内核。(flashattn!!!我要编译你,一百遍也不够!!!)
- 只在assistant token上计算loss(换句话说,SFT的时候把题目mask掉)
- 调整学习率
- pack训练样本,并且根据你的数据分布调整序列长度。
作者对数据混合做了一些实验:
- Instruct:在非推理数据上训练
- Thinking:在推理数据上训练
- Hybrid:混合
结论是:混合模型表现出了一种“split brain”,推理模式的数据对另一种模式几乎没有影响。(混合数据提高了整体性能)
Vibe-test your baselines
eval跑起来看上去还好,但当作者试着让混合模型扮演不同角色的时候,发现这个模型会始终忽略system prompt的内容。最终发现原因是数据格式化的bug导致的(导致每个训练样本的system message都被移除了)。
如果不实际采样一些case看看,是发现不了这个问题的。
Targeting specific capabilities
在Open-R1的训练中,作者注意到,完全在单轮推理数据上训练的base模型将无法泛化到多轮。因为实际上测试Out of Distribution了。Qwen3对此的做法是做了个内部评估(叫ThinkFollow),这个评估会随机插入“/think”和“/no_think”tag,测试模型能不能一致地切换推理模式。作者们也实现了这个评估,发现模型会在第一轮之后无法打开推理模式。
为了修复这个能力,作者构建了一个新的数据集(IFThink)。是用Qwen3-32B将Tulu-3的IF subset(单轮对话)扩展成多轮(带有可验证指令和推理轨迹)的交流。
graph TB
A[Tulu3 IF Dataset] --> B[Single turn prompt]
A --> C[Set of instruction types]
B --> D[Prompt at turn 1]
C --> E[Generate instructions with Qwen3-32B]
D --> F[Generate reasoning traces with Qwen3-32B]
E --> G[Prompt at turn 2]
E --> H[Prompt at turn 3]
F --> I[IFThink]
G --> F
H --> F
style A fill:#ffcdd2
style C fill:#ffcdd2
style I fill:#e1f5fe
which hyperparameters actually matter
SFT里,只有几个超参数有用:学习率、batch size、packing。几乎决定了训练效率和泛化能力。(如果忽略LoRA,只考虑FullFT的话)
作者做了一些实验,以下是结论:
- 要不要mask掉user message,只预测assistant message:除了在IFEval上,对其他下游任务的评估影响不大
- pack还是不pack:pack把吞吐量提高了3~5倍,但可能会轻微改变训练动态和性能(因为进行的梯度更新次数少了)。比如在有效batch size 128下,pack会导致IFEval性能下降10个点。实际上根据作者的实验,只要有效batch size大于32,性能就会下降。结论是:对于大规模SFT,肯定得用pack(少更新几次梯度影响不大),但对于更小/多样化的数据集,禁用pack能确保每个样本都为优化做出贡献。
- 学习率:一般比预训练小一个数量级以上,好图不好放,建议这里看看原文的图。。从图里看上去,3e-5大体上是个很不错的值(除了AIME25等,学习率大于1e-5就会暴跌)。
- epoch数:消融实验一般只训一轮快速迭代,而正式训练可以多训几轮,再压榨一些性能出来。
- 优化器:默认用AdamW,不确定的是要不要换用Muon等等(Kimi一直在用)。
Boosting reasoning through continued pretraining
Continued Pretrain(或者叫mid-training)指的是SFT之前,在base模型上进一步训练。这会把模型转向一个更好支持你关心的能力的分布。而在 Phi-4-Mini-Reasoning 中,作者在Deepseek-R1蒸馏出的推理token上做了增训,结果很不错。
这里作者们从三个候选数据集出发:
- Mixture of Thoughts:350k个推理问题(DeepSeek-R1蒸馏出的数学、代码、科学领域)
- Llama-Nemotron-Post-Training-Dataset:Nvidia的大规模数据集,从Llama3和Deepseek-R1等蒸馏出来,大约3.64M个sample,18.7B token
- OpenThoughts3-1.2M:高质量推理数据集,1.2M个从QwQ-32B蒸馏的sample,包括16.5B token
作者们将Mixture of Thoughts用于SFT,将其他用于增训。用了ChatML作为chat template,避免固化SmolLM3的模板。以2e-5的学习率训了5轮(8个节点,有效batch size 128)
Q: When to mid-train?
A: You might wonder why we’re discussing mid-training after we did some SFT runs. Chronologically, mid-training happens before SFT on the base model. But the decision to do mid-training only becomes clear after you’ve run initial SFT experiments and identified performance gaps. In practice, you’ll often iterate: run SFT to identify weak areas, then do targeted mid-training, then run SFT again. Think of this section as “what to do when SFT alone isn’t enough.”
☝️Rule As we emphasized in pre-training, save model checkpoints frequently during a training run, and ideally push them to the Hugging Face Hub to avoid accidental overwrites. Also, make your training framework robust to failures and capable of automatic restarts. Both of these strategies will save you time, especially for long-running jobs like mid-training ones.
总的而言,这里的实验结果是:
- Nvidia的后训练数据集比OpenThoughts更好,但两个混起来最好。
- 增训(Mid-training)效果显著,增训后的模型在AIME和LiveCodeBench上翻了三倍。GPQA也提升了10个点。
所以结论是:对于推理模型,如果基础模型在预训练阶段没见过大量推理数据,那么进行一定的增训几乎总是有用的。
From SFT to preference optimisation: teaching models what better mean
SFT的收益会递减,因为只是在模仿学习,模型得不到明确的“更好”信号。所以需要偏好优化(Preference Optimization)作者原文使用的是Optimisation,我个人认为是typo,但为了表示尊重原文,这里就先保留不改,但涉及到我自己写的内容,都会使用optimization
PO的好处在于:1. 更直接的训练信号,能超越SFT的局限;2. 需要数据量远少于SFT
Creating preference datasets
此前(RLHF+PPO)偏好数据集是人类标注者从成对的模型响应中选出一个更好的。这昂贵而又难以扩展。所以一个做法是用较弱的模型和较强的模型对同一个prompt生成响应,然后假设较弱模型的回答比较强模型的回答差。
On-Policy:
- 使用被训练的同一个模型生成多个候选响应,这是on-policy,反映了模型自然生成的输出分布。
- 引入一个外部的打分者:比如Verifier或者Reward Model,而不是把强模型作为reference。
- 打分者在候选响应中打标,产生一个更灵活的偏好数据集,但依赖于打分者的可靠性。
Which algorithm do I pick?
- DPO:在开源领域广泛采用,实现简单、稳定,少量偏好数据也很有效
- KTO:不依赖于偏好对
- ORPO:在SFT的交叉熵损失中直接加入一个odds ratio,计算效率高
- APO
下面三个都是DPO的扩展,代码改动也不大
作者们实验发现APO-zero有着最好的OD泛化性能,所以接下来的消融里都是用APO-zero
Which hyperparameters matter most for preference optimisation
- 学习率,一般比SFT要小10~100倍
- \beta,控制偏好对之间的距离
- batch size
首先第一个实验是学习率:PO的最佳学习率大约小10倍。作者建议在比SFT小5~20倍的范围内扫描学习率。
第二个实验是beta:太低的beta会和参考模型接近,而太高的beta会紧密匹配偏好数据。作者建议使用beta=0.1(或更大),或者在0.01到0.5之间探索。
第三个实验是数据集大小:看上去数据集规模影响不大,性能大体上稳定。
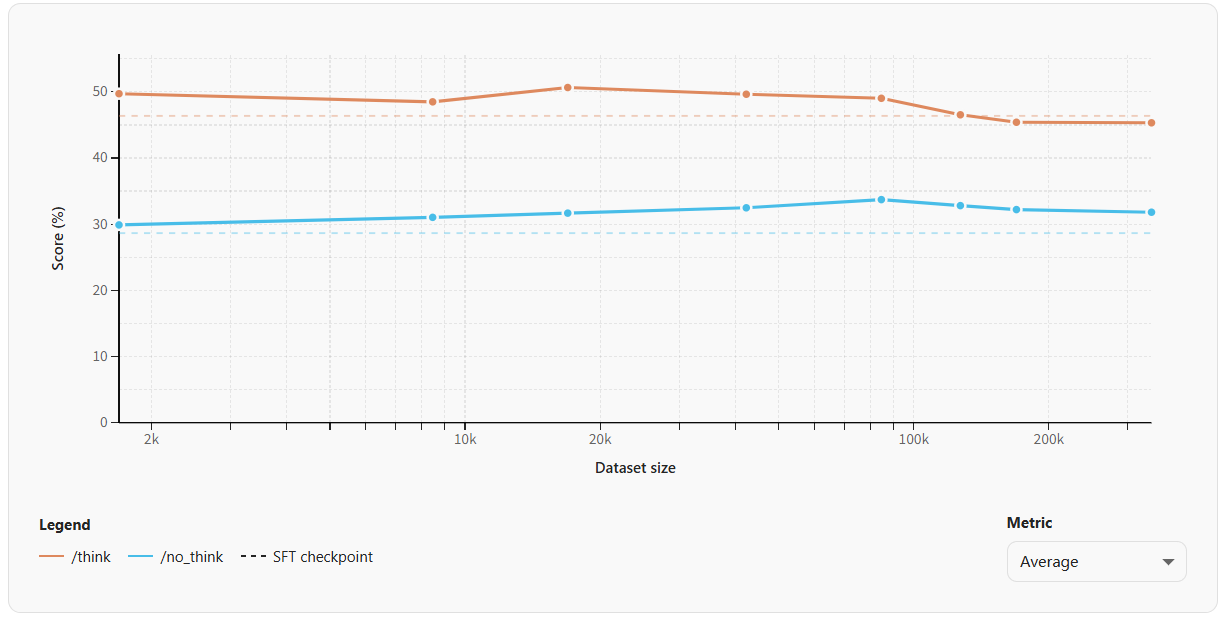
Rules of engagement
- Don’t be afraid to create your own preference data! With inference becoming “too cheap to meter”, it’s nowadays simple and cost-effective to generate LLM preferences from various inference providers.
- Pick DPO as your initial baseline and iterate from there. We’ve found that depending on the type of preference data, other algorithms like ORPO, KTO, or APO can provide significant gains over DPO.
- Use a learning rate that’s around 10x smaller than the one used for SFT.
- Scan over β, usually in the range 0.01 to 0.5
- Since most preference algorithms overfit after one epoch, partition your data and train iteratively for best performance.
PO基本上是简单和性能之间的平衡点,但限制在于offline的偏好数据是上限,静态数据集的信号有限。所以需要更广泛的on-policy方法。